关于如何用 2-Component 共享词向量来优化 RNN。
原文:LightRNN: Memory and Computation-Efficient Recurrent Neural Networks
部分译文: 微软重磅论文提出LightRNN:高效利用内存和计算的循环神经网络
这里只是稍微总结一下。
研究问题
LightRNN 解决的问题是在 perplexity 差不多的情况下 减少模型大小(model size) + 加快训练速度(computational complexity)。论文在多个基准数据集进行语言建模任务来评价 LightRNN,实验表明,在困惑度(perplexity)上面,LightRNN 实现了可与最先进的语言模型媲美或更好的准确度,同时还减少了模型大小高达百倍,加快了训练过程两倍。这带来的意义无疑是深远的,它使得先前昂贵的 RNN 算法变得非常经济且规模化了,RNN 模型运用到 GPU 甚至是移动设备成为了可能,另外,如果训练数据很大,需要分布式平行训练时,聚合本地工作器(worker)的模型所需要的交流成本也会大大降低。
主要思路
单词表示(Word Representation)
主要思路是使用 二分量(2-Component) 来共享 embeddings。
将词汇表中的每一个词都分配(或者说填入)到一个二维表格中,然后每一行关联一个向量,每一列关联另一个向量。根据一个词在表中的位置,该词可由行向量和列向量两个维度联合表示。表格中每一行的单词共享一个行向量,每一列的单词共享一个列向量,所以我们仅需要 $2 \sqrt |V|$ 个向量来表示带有|V|个词的词汇表,远少于现有的方法所需要的向量数|V|。
$x^r_i$: 第 i 行
$x^c_j$: 第 j 列
引入 RNN
知道了怎么用两个向量来表示一个词语,下一步就是如何将这种表示方法引入到 RNN 中。论文的做法非常简单,将一个词的行向量和列向量按顺序分别送入 RNN 中,以语言模型(Language Model, LM)为例,要计算下一个词是 $w_t$ 的概率,先根据前文计算下一个词的行向量是 $w_t$ 的概率,在根据前文和 $w_t$ 的行向量来计算下一个词的列向量是 $w_t$ 的概率,行向量和列向量的概率乘积就是下一个词是 $w_t$ 的概率。
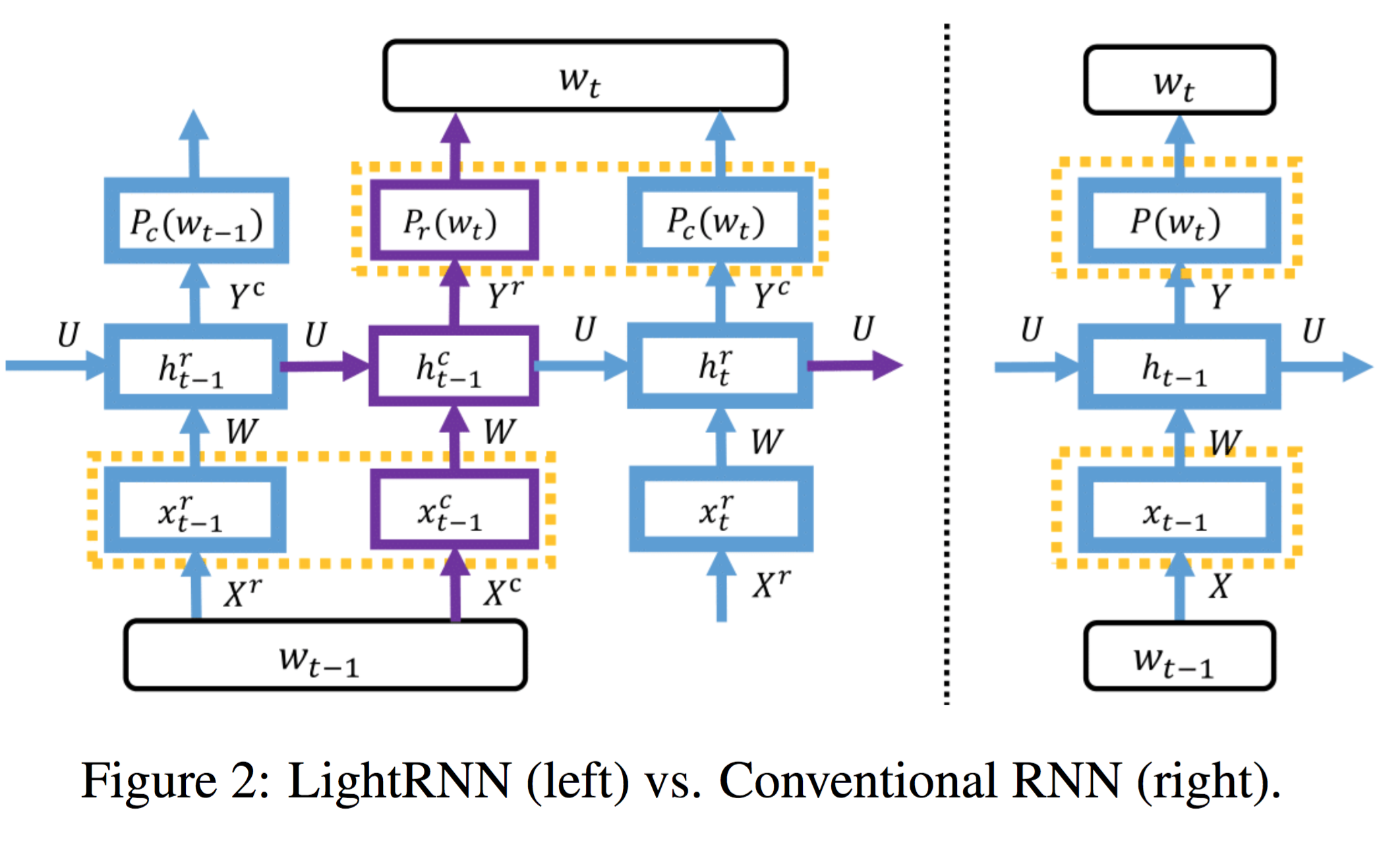
单词分配
怎么来分配单词形成这个表格呢?
- 对冷启动(cold start)来说,随机初始化分配单词
- 对给定的 allocation 训练 embedding vectors 直到收敛(convergence)
停止条件(stopping criterion)可以是训练时间或者是 perplexity(for LM model) - 固定上一步中学习到的 embedding vectors,重新分配单词(refine allocation),标准当然是最小化损失函数了
损失函数/优化问题
损失函数:
交叉熵(corss-entropy)
给定 T 个单词,损失函数 NNL(negative log-likelihood) 为:
$$NNL = \sum^T_{t=1}-logP(w_t)=\sum^T_{t=1}-logP_r{w_t}-logP_c(w_t)$$
扩展一下,$NNL=\sum^{|V|}_{w=1}NLL_w$,而单词 w 的损失函数 $NNL_w$ 为:
$$
\begin{aligned}
NNL_w & = \sum_{t \in S_w} -logP(w_t) = l(w,r(w),c(w))\\
& = \sum_{t \in S_w} -logP_r(w_t)+ \sum_{t \in S_w} -logP_c(w_t) = l_r(w,r(w)) + l_c(w,c(w)) \\
\end{aligned}
$$
- $S_w$: 单词 w 的所有可能出现的位置的集合
- $(r(w),c(w))$: 单词 w 在 allocation table 的位置
- $l_r(w,r(w))$: 单词 w 的行损失(row loss)
- $l_c(w,c(w))$: 单词 w 的列损失(column loss)
假定 $l(w,i,j)=l(w,i)+l(w,j)$ 的情况下,计算 $l(w,i,j)$ 的复杂度是 $O(|V|^2)$,而事实上,所有的 $l_r(w,i)$ 和 $l_c(w,j)$ 都在 LightRNN 训练的前向传播中计算过了。对所有的 $w,i,j$ 计算 $l(w,i,j)$ 后,我们可以把 reallocation 的问题看做下面的优化问题:
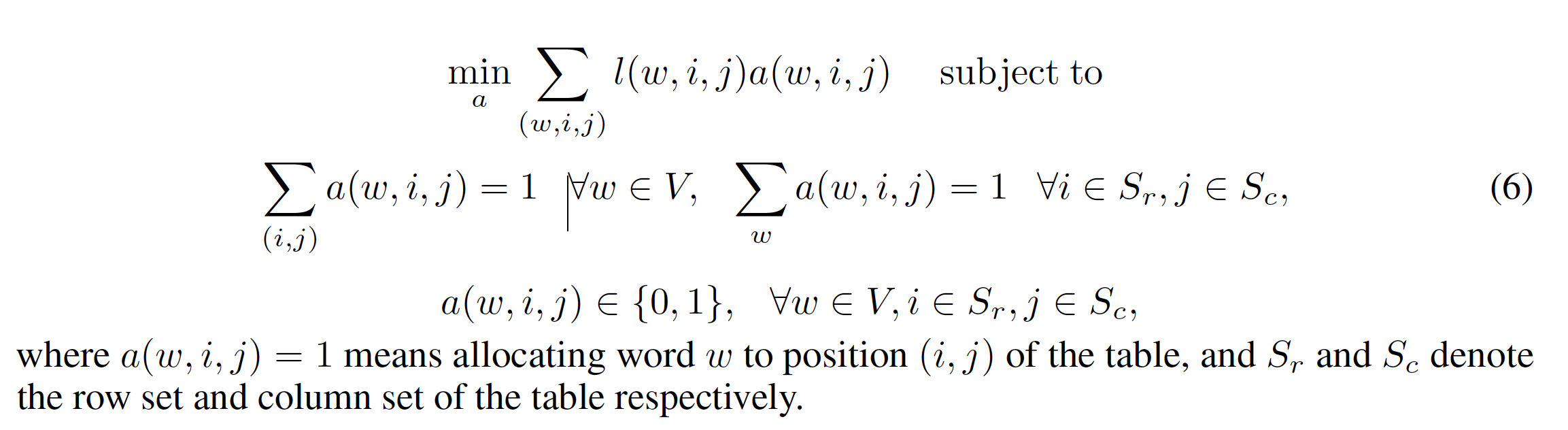
这个优化问题又可以等价为一个标准的 最小权完美匹配(minimum weight perfect matching problem),可以用 minimum cost maximum flow(MCMF) 算法来实现,复杂度为 $O(|V|^3)$,主要思路大概如下图,论文的实验中用的是一个最小权完美匹配的近似算法 1/2-approximation algorithm,复杂度为 $O(|V|^2)$,这和整个 LightRNN 的训练复杂度(约为 $O(|V|KT)$,K 是训练过程的 epoch 数,T 是训练集中的 token 总数)比起来不算什么。
相关工作


[1] Ravindra K Ahuja, Thomas L Magnanti, and James B Orlin. Network flows. Technical report, DTIC Document, 1988.
[2] Jeremy Appleyard, Tomas Kocisky, and Phil Blunsom. Optimizing performance of recurrent neural networks on gpus. arXiv preprint arXiv:1604.01946, 2016.
[3] Yoshua Bengio, Jean-Sébastien Senécal, et al. Quick training of probabilistic neural nets by importance sampling. In AISTATS, 2003.
[4] Jan A Botha and Phil Blunsom. Compositional morphology for word representations and language modelling. arXiv preprint arXiv:1405.4273, 2014.
[5] Ciprian Chelba, Tomas Mikolov, Mike Schuster, Qi Ge, Thorsten Brants, Phillipp Koehn, and Tony Robinson. One billion word benchmark for measuring progress in statistical language modeling. arXiv preprint arXiv:1312.3005, 2013.
[6] Welin Chen, David Grangier, and Michael Auli. Strategies for training large vocabulary neural language models. arXiv preprint arXiv:1512.04906, 2015.
[7] Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555, 2014.
[8] Felix A Gers, Jürgen Schmidhuber, and Fred Cummins. Learning to forget: Continual prediction with lstm. Neural computation, 12(10):2451–2471, 2000.
[9] Joshua Goodman. Classes for fast maximum entropy training. In Acoustics, Speech, and Signal Processing, 2001. Proceedings.(ICASSP’01). 2001 IEEE International Conference on, volume 1, pages 561–564. IEEE, 2001.
[10] Alex Graves. Generating sequences with recurrent neural networks. arXiv preprint arXiv:1308.0850, 2013.
[11] Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural computation, 9(8):1735–1780, 1997.
[12] Shihao Ji, SVN Vishwanathan, Nadathur Satish, Michael J Anderson, and Pradeep Dubey. Blackout: Speeding up recurrent neural network language models with very large vocabularies. arXiv preprint arXiv:1511.06909, 2015.
[13] Yoon Kim, Yacine Jernite, David Sontag, and Alexander M Rush. Character-aware neural language models. arXiv preprint arXiv:1508.06615, 2015.
[14] Tomas Mikolov, Martin Karafiát, Lukas Burget, Jan Cernocky, and Sanjeev Khudanpur. Recurrent neural network based language model. In INTERSPEECH, volume 2, page 3, 2010.
[15] TomášMikolov, Stefan Kombrink, Lukáš Burget, Jan Honza Cˇ ernocky, and Sanjeev Khudanpur. Extensions of recurrent neural network language model. In Acoustics, Speech and Signal Processing (ICASSP), 2011 IEEE International Conference on, pages 5528–5531. IEEE, 2011.
[16] Andriy Mnih and Geoffrey E Hinton. A scalable hierarchical distributed language model. In Advances in neural information processing systems, pages 1081–1088, 2009.
[17] Frederic Morin and Yoshua Bengio. Hierarchical probabilistic neural network language model. In Aistats, volume 5, pages 246–252. Citeseer, 2005.
[18] Christos H Papadimitriou and Kenneth Steiglitz. Combinatorial optimization: algorithms and complexity. Courier Corporation, 1982.
[19] Jan Pomikálek, Milos Jakubícek, and Pavel Rychl`y. Building a 70 billion word corpus of english from clueweb. In LREC, pages 502–506, 2012.
[20] Robert Preis. Linear time 1/2-approximation algorithm for maximum weighted matching in general graphs. In STACS 99, pages 259–269. Springer, 1999.
[21] Ha¸sim Sak, Andrew Senior, and Françoise Beaufays. Long short-term memory based recurrent neural network architectures for large vocabulary speech recognition. arXiv preprint arXiv:1402.1128, 2014.
[22] Martin Sundermeyer, Ralf Schlüter, and Hermann Ney. Lstm neural networks for language modeling. In INTERSPEECH, pages 194–197, 2012.
[23] Ilya Sutskever, Oriol Vinyals, and Quoc V Le. Sequence to sequence learning with neural networks. In Advances in neural information processing systems, pages 3104–3112, 2014.
[24] Duyu Tang, Bing Qin, and Ting Liu. Document modeling with gated recurrent neural network for sentiment classification. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1422–1432, 2015.
[25] Paul J Werbos. Backpropagation through time: what it does and how to do it. Proceedings of the IEEE, 78(10):1550–1560, 1990.
[26] Jason Weston, Sumit Chopra, and Antoine Bordes. Memory networks. arXiv preprint arXiv:1410.3916, 2014.
[27] Dong Yu, Adam Eversole, Mike Seltzer, Kaisheng Yao, Zhiheng Huang, Brian Guenter, Oleksii Kuchaiev, Yu Zhang, Frank Seide, Huaming Wang, et al. An introduction to computational networks and the computational network toolkit. Technical report, Technical report, Tech. Rep. MSR, Microsoft Research, 2014, 2014. research. microsoft. com/apps/pubs, 2014.
[28] Wojciech Zaremba, Ilya Sutskever, and Oriol Vinyals. Recurrent neural network regularization. arXiv preprint arXiv:1409.2329, 2014.

